
はじめましての方ははじめまして。そうでない方もごきげんよう。
バックエンドエンジニアの@mobojisan と申します。
月日の流れは早いもので、僕がクロスマートTech Blogに記事を書くのも5回目となり、さまざまな人がブログを書いてくださるようになったことで、
間隔がだんだんと空いてきていることに、事業とプロダクトの成長をひしひしと身にしみて感じています。
そして月日の流れよりも早いものがありますよね!
ChatGPTなどでおなじみ、LLM(大規模言語モデル)の進歩です!もはや数分ごとに新しい何かしらが出ているといっても過言ではありません。
Metaが擁するLlamaがついこないだ3になったと思ったら、MicrosoftのPhiは出た瞬間に3になり、そのうえWindows上でローカルLLMが動くよう、アップデートが入ることすらリリースされています。
大本命、OpenAIも気がついたらGPT-4oがリリースされて、各々の話題をかっさらって行ったことは記憶に新しいです。
GPT-4oでは、マルチモーダルな入出力面での進歩が目覚ましかったですよね。
その中でもデータの入出力にネイティブで対応したことは、個人的に強く印象に残りました。
そんなテーブルデータの取り扱いのネイティブサポートに関連して、今回はDBを対象としたRAGを得意とするvannaの紹介です。
vannaとは?
RAG、Retrieval-Augmented Generation(検索拡張生成)という、LLM(大規模言語モデル)に追加的かつ外部的に、情報を追加する手法があります。
ひとことでいえば、vannaはそんなRAGを利用してLLMに追加のコンテキストを与え、対象への洞察を加味した正確なSQL生成やPlotlyサポートによるデータ可視化を可能にするライブラリです。
https://openai.com/index/improvements-to-data-analysis-in-chatgpt/
ちなみに、先日リリースされたGPT-4oではデータ分析の機能が強化され、テーブルやCSVをネイティブで読み込み、対話形式でデータ分析を可能にするアップデートが入りました。
vannaはGPT-4oでネイティブサポートされたデータ分析機能を強化したようなプロダクトで、 DBのスキーマとそのデータを直接読み込むことができます。
また、ユーザーが使用するにつれてモデルが自動的に改善され、SQLの作成を自動化してくれます。
ドメイン知識と過去の回答をふまえ、次の質問をより正確に答えることができます。
事前準備
用意すべきは以下の3点。
オープンソースであるため、この3点セットをすべてセルフホストで運用することもできます。
そのため、質問に使うLLMモデルはOllamaやAzure Open AIなどを利用したものに変更し、独自のインフラストラクチャ上で運用できます。ビジネスユースでも安心。
もちろんvannaにホストされたLLMとベクターDBを使用することもできます。これを使った場合20行弱でドメイン知識を理解した対話型ChatBotが完成してしまいます。
加えて、元データのソースであるDBについても、MySQLやPostgresSQLはもちろん、snowflakeやBigqueryからのインポートをサポートしています。なんでもインポートできてしまいますね。
GPT-4oのネイティブデータ読み込み機能との違いは、元データをDBから読み込めることと、継続的な学習による回答の最適化が可能なこと。
運用を考えると、GPT-4oを利用してデータ分析しようとする場合、
元データをxmlなどの形式でテーブルごとに吐き出してGoogle Driveなどに置き、
コンテキストをプロンプトとして与えつつ、
さらに十分な量の回答例を考えて入力
する必要があります。
それからやっとの思いで質問しても以下画像の真ん中のグラフの正答率です。けっこう面倒ですよね。
vannaはそうした面倒さを一気通貫で解消し、以下画像右のグラフの万全の状態から質問を始めることができるのです。
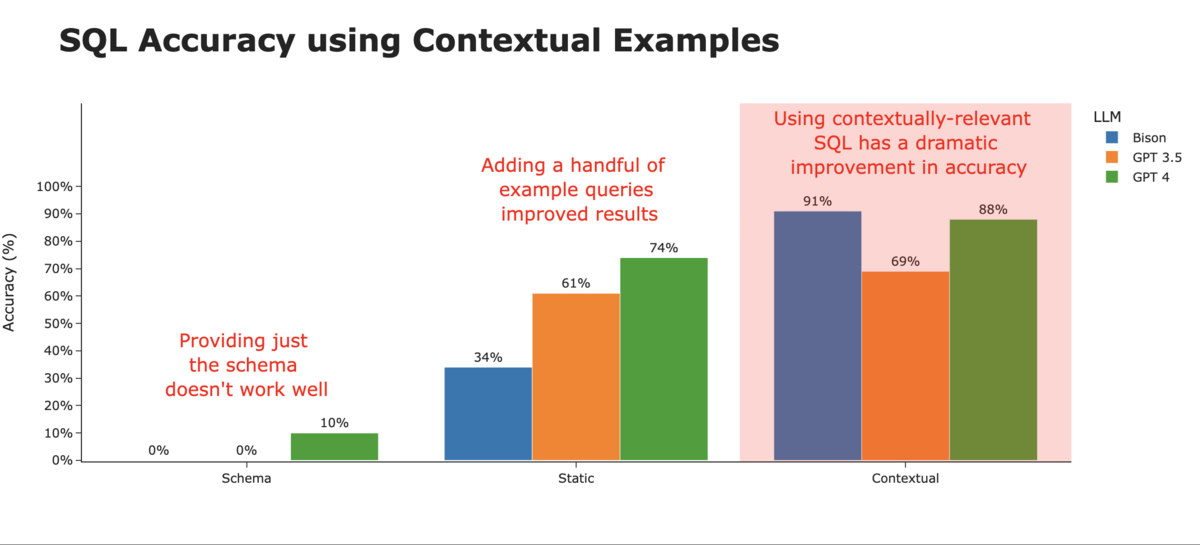
グラフは以下リンクから引用しています。
How accurate can AI generate SQL?
今回はあらかじめ用意したOpenAIのAPIキーとvannaにホストされたベクターDBを使用してみます。
vannaを導入
導入は非常に簡単です。 以下に登録してvannaのAPIキーを取得します。
class MyVanna(VannaDB_VectorStore, OpenAI_Chat): def __init__(self, config=None): MY_VANNA_MODEL = 'chinook' # サンプルのDBモデル MY_VANNA_API_KEY = 'APIキー' VannaDB_VectorStore.__init__(self, vanna_model=MY_VANNA_MODEL, vanna_api_key=MY_VANNA_API_KEY, config=config) OpenAI_Chat.__init__(self, config=config)
これだけでもvannaを通してLLMを利用できますが、OpenAI APIを使いたい場合、
以下のようにMyVannaクラスをオーバーライドしましょう。
vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-3.5-...'})
このようにするだけで、すべての事前設定が完了しています。
あとは、DBを読み込み、質問するだけですね。
vannaを実行
今回は、サンプルとしてvannaからSQLiteで提供されているDBを利用してみます。
vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite') from vanna.flask import VannaFlaskApp VannaFlaskApp(vn).run()
準備が完了しました。Flaskでチャットウィンドウが立ち上がりますが、コマンドでも可能です。早速質問してみましょう。
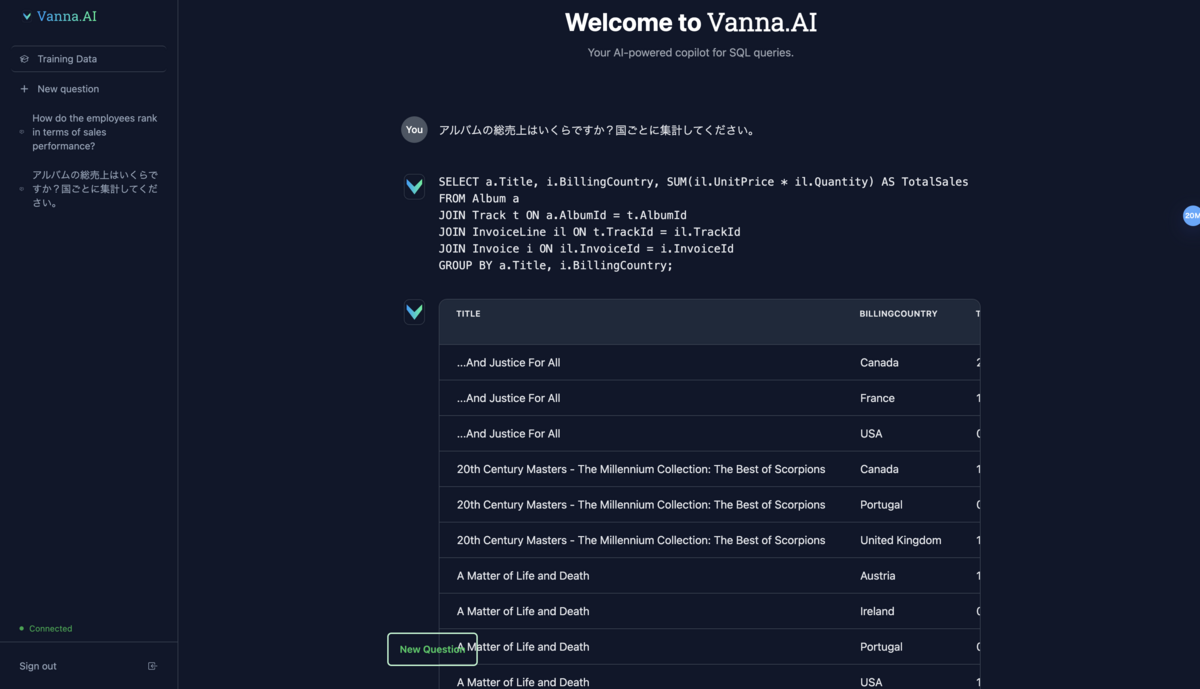
vn.ask(question='アルバムの総売上はいくらですか?国ごとに集計してください。')
発行されたSQLは以下の通りで、SQLとしては問題がなさそうに見えます。
SELECT a.Title, i.BillingCountry, SUM(il.UnitPrice * il.Quantity) AS TotalSales FROM Album a JOIN Track t ON a.AlbumId = t.AlbumId JOIN InvoiceLine il ON t.TrackId = il.TrackId JOIN Invoice i ON il.InvoiceId = i.InvoiceId GROUP BY a.Title, i.BillingCountry;
回答は以下のような感じでした。
vannaにはWebUIがデフォルトでついてきており、この対話ウィンドウ上では実行ごとにCSVとしてデータを出力可能です。
また、実行結果が有効だった場合、PlotlyでCSVをグラフ化したデータも表示されています。
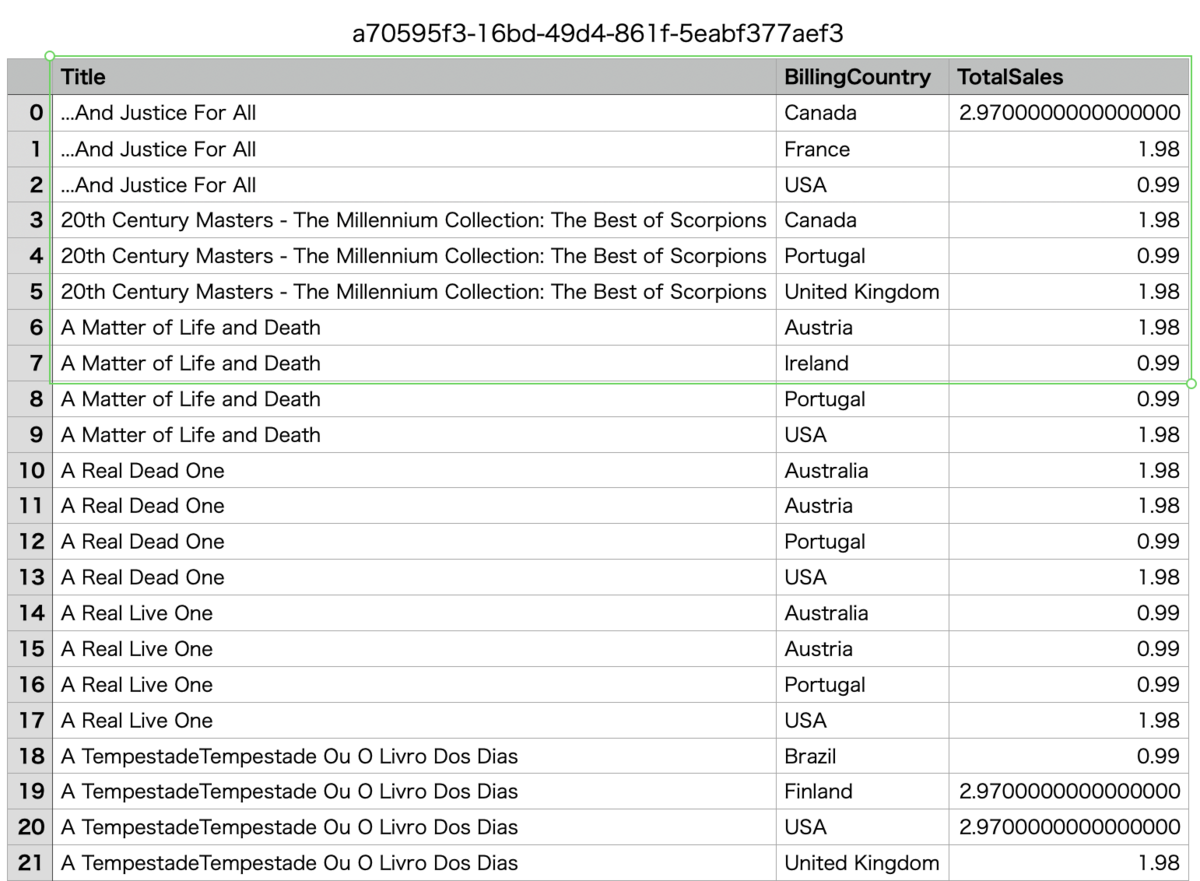
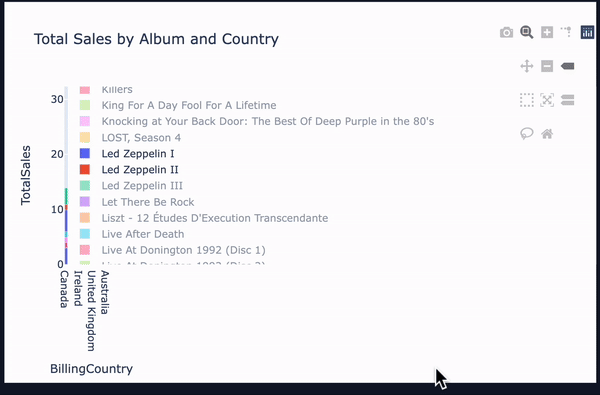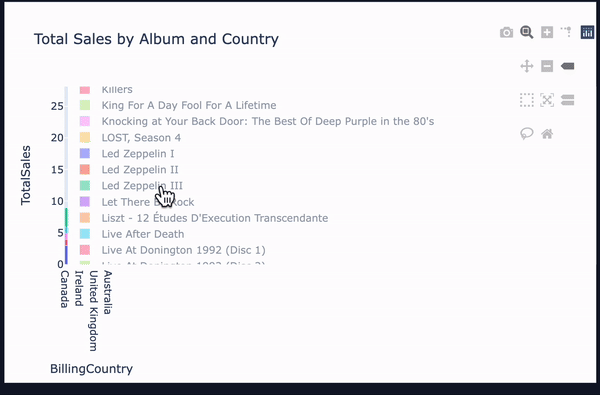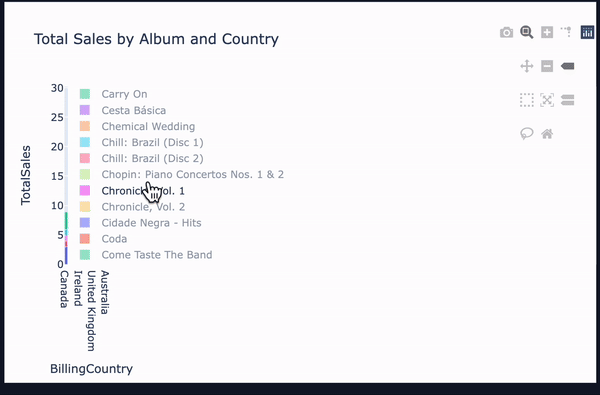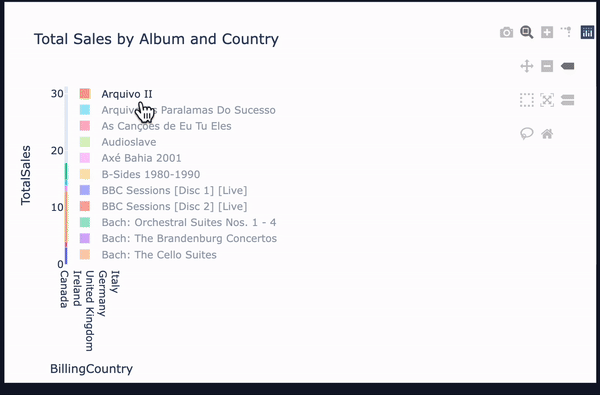
回答の質は元データにかなり左右される雰囲気を感じましたが、回答に不満がある場合、
SQLを直接修正することもでき、単純なSQL実行およびダッシュボードを表示するためのクライアントとしても使えそうでした。
個人的な感想ですが、学習データに読み込ませるDDLと質問を改善することで、さらなる精度向上の余地がありそうに思いました。
とはいえ、クエリの叩き台として使い、データをインタラクティブなグラフで表示してくれる点で、データ探索にはかなり便利な気がしました。
スキーマの情報をRAGで入れていることもあり、ハルシネーションこと、幻覚によって存在しないカラムを提案されることが少ないのは好感でした。
あと、今回GPT3.5-turbo系を使っているのでGPT-4o系に上げるだけで単純に精度が爆上がりしそうな気もしますね…
加えて、チャットウィンドウ内でSQLが自動で走り実行結果が見えることで、認知負荷がかなり少ないのも気持ちが良かったです。
具体的なChatGPTとの比較でいえば、ChatGPTに対していっさいコンテキストをあたえることなくクエリに関する質問をしていると、質問しているうちに構文エラーが含まれるSQLなどを吐き出したり、質問内容を忘れたりします。
そのため対話しながらクエリを書くことに精神的な負荷を覚えていました。
その点、vannaのようにRAGで必要な情報をあらかじめトレーニングしておく、という方向性はChatGPTの嘘を画期的に減らせるため、筋が良さそうなアプローチに思います。
データがないとき、vannaはどうなるか
明らかにデータに含まれなさそうな質問をしてみましょう。
vn.ask(question="ニコラス・ケイジが俳優として出演した映画は何本ありますか?")
LLMだとハルシネーションでそれっぽいデータを出してくることがありますが、この場合見つかってほしくないですよね!
上の質問の結果実行されるSQLの結果はエラーになっていました。
Couldn't run sql: (1054, "Unknown column 'movies_performed' in 'field list'")
回答もこんな感じで、見つからなかったことが明記されています。
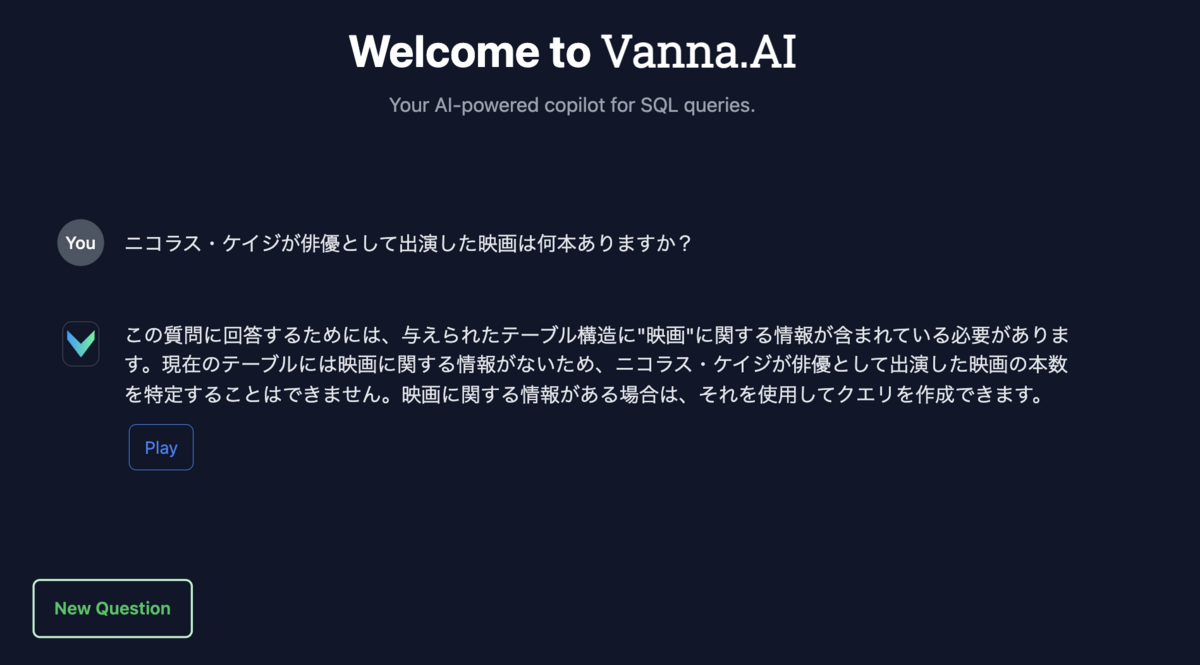
なお、上でVannaFlaskApp.run()した際にはflask製のWebUIが立ち上がり、vn.ask()を裏側で実行する画面がありましたが、
SlackやStreamlitにもデフォで対応しているようで、業務ツールへの組み込みも容易なようでした。いたつくですね!
GitHub - vanna-ai/vanna-slack: Slack bot for Vanna AI
あとがき
いかがでしたでしょうか?
今回は、対話形式でいい感じにデータを取れるvannaについて紹介しました。
以下のリンクから、リソースを選ぶだけでそのままペロッと実行できる素敵なjupyter notebookがダウンロードできます。
ローカルLLMやローカルベクターDBを選択すると準備は増えますが、notebookから比較的簡単に実行できますのでぜひ、お手持ちのデータでトライしてみてください。
話は変わりますが、弊社クロスマートでは新卒中途問わず、ポジションはさまざまにエンジニアを募集しております。
この記事を通して少しでもご興味持っていただけましたら、カジュアルだけでも結構ですとは立場上言えませんが、どうぞカジュアルな流れでカジュアル面談をお願いします!